
HANA
What is Data Pruning?
Pruning consists of strategies on how to avoid scanning sections of data that you know will not be required for calculations in queries. For example, if you are running a sales report for the year 2020, there is no need to aggregate data from 2019, as all that internal work is thrown out at the end. Pruning strategies span across the entire HANA architecture, from how you structure your tables to configuring your calculation views. There are ways to prune data at the table level, such as partition pruning, and calculation view level, such as a union node pruning. In this post, we will discuss table partition pruning and the two methods of pruning at the union node level within a calculation view.
HANA Partition Pruning
When you create tables in HANA, you have the option to partition the table’s data into sections. These sections can span across different nodes in a distributed environment. It is also a very common way to overcome the maximum row limit (two billion), as each partition will have that limit. From a query processing point of view, you can use partitions to restrict the amount of data required to process at a very early stage, which will pay huge dividends in terms of processing time. Please note that you will only get the performance improvements if the query predicates match the partitioning criteria.
The costs of table partitioning must be considered as well. When you specify a HANA table to be partitioned, each new partition will be treated as its own table, so to speak. Each will have its own private delta and main table parts, as well as dictionaries that are separate from those of the other partitioning. If a query requires full iteration across the entire dataset and partitions, it could take longer than if the table weren’t partitioned at all due to this overhead. In other words, make sure your partitioning criteria allows most of your most frequent/expensive queries to take advantage of the pruning.
Union Node Pruning
Now, let us talk about various ways to increase performance via pruning when data modeling is at the calculation view level. The first way to approach this is when you are bringing in several data sources via a UNION. The idea is to only involve the data sources you require for the final result. Union node pruning requires some configuration so that at runtime, data can be excluded from data sources that are not required for final processing. There are two ways to do this: pruning config table and constant mapping.
A pruning config table involves using a table (or view) to specify the data slices contained in the individual data sources. For example, you can divide up the data slices by year, by department, etc. When a query is run, the engine attempts to match to the query filter, so that only the required data sources are processed, while the ones not required are ignored completely.
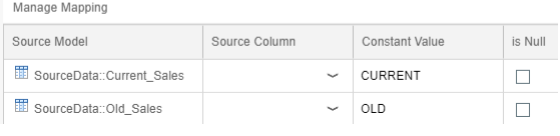
The alternative to pruning config table is using constant mapping. Within a union node, you create a constant that will differentiate between the two sources. The constant column is then mapped across the underlying data sources. The benefit of this option over the config table option above is that constant mapping will perform better, however, it comes at the expense of being less flexible.
Conclusion
Pruning strategies are very effective in eliminating unnecessary operations in your HANA system. The idea is to avoid having to query data you know in advance will not produce any relevant results as early as possible. Table partitioning and union node pruning are only a few of the recommended best practices to keep your solutions performing at the optimal levels.
For more information on this, reach out to us here: https://ameri100.com/contact/?r=1